Multiplayer SDKs & Patterns
Multiplayer verstehen - Teil II
Im ersten Beitrag haben wir uns angesehen, was Multiplayer-Anwendungen ausmachen, was für ein grundsätzliches Verständnis notwendig ist und welche häufigen Missverständnisse existieren. In diesem Beitrag ergründen wir die Frage danach, was für Infrastruktur und SDKs für Multiuser-Anwendungen notwendig sind und was sich im Detail im Source-Code ändern muss, um eine bestehende Anwendung um eine Multiplayer-Funktion zu erweitern.
Infrastruktur
Da wir in diesem Fall nur über Netzwerk-Multiplayer sprechen, können wir davon ausgehen, dass es immer zumindest einen Server und zwei Clients gibt, um eine Anwendung im Multiplayer erleben zu können.
Zunächst gehen wir darauf ein, aus welchen Komponenten sich eine Topologie zusammensetzen kann. Wobei die Topologie die Aussage darüber trifft, was ein Server ist und was ein Client. Wie wir sehen werden, gibt es auch Fälle, in denen beides dasselbe ist.
-
Transport Layer. Beschreibt die Protokolle und Werkzeuge, mit welchen die Daten versendet und synchronisiert werden.
-
Client Runtime Application. Die Runtime welche von Clients verwendet wird.
-
Server Runtime Application. Die Runtime, welche vom Server verwendet wird.
Backend Services. Standalone Services für Matchmaking, Leaderboards, Friend-Lists, usw.
Player-Hosted P2P
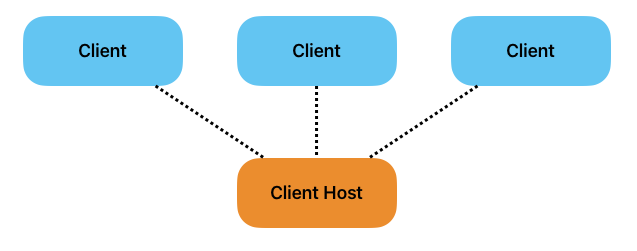
In einem Peer-to-Peer Netzwerk gibt es keinen Server im klassischen Sinne. Stattdessen agiert einer der Clients gleichzeitig als Server – ein sogenannter Host – mit dem sich andere Clients verbinden.
-
Kostengünstig. Ohne die Notwendigkeit für einen klassischen Server, welcher dediziert gehostet werden müsste, sinken die Kosten für einen Multiplayer auf ein Minimum.
-
Relay Server. Für den Fall, dass der Multiplayer über das Internet möglich sein soll und nicht nur über ein lokales Netzwerk, wäre ein Relay Server notwendig, welcher die Verbindung zwischen beiden Peers initiiert und verwaltet. Andernfalls müssten User*innen bestimmte Ports bei ihren Routern freigeben, was je nach Zielgruppe und Anwendungsfall sehr unpraktisch sein kann.
-
Host Autorität. In Anwendungen und Spielen mit einem kompetitiven Charakter besitzt der Host einen signifikanten Vorteil gegenüber den verbundenen Clients, da er mit keiner Latency rechnen muss – Client und Server laufen auf demselben Gerät. Auch kann nicht verhindert werden, dass der Host den Game-State zu seinen Gunsten manipuliert. Was bei Anwendungen, mit einer Priorität auf Datenintegrität ein schwerwiegendes Problem darstellt.
-
Host-Migration. Verlässt der Host das Spiel, bedeutet das auch einen Verbindungsabbruch für alle anderen Clients. Eine Gegenmaßnahme ist Host-Migration, welche einen anderen Client zu Host und den gesamten State inklusive der Autoritäten ihm überträgt. Dies kann je nach Anwendungsfall ein komplexer und fehleranfälliger Prozess sein, welcher in jedem Fall das Benutzerlebnis unterbricht.
Host Performance. Das Gerät, welches als Host agiert, hat eine erhöhte Last. Da es neben der Server-Runtime auch die Client-Runtime verarbeiten muss. Bei Geräten mit begrenzter Performance kann das zu Problemen führen.
Direct P2P
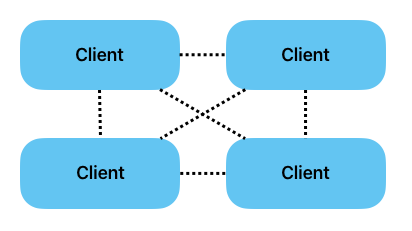
In einem direkten Peer-to-Peer Netzwerk verbinden sich die Clients direkt miteinander und agieren jeweils auch als Server. Neben den Vor- und Nachteilen einer Player-Hosted Lösung kommen noch weitere Punkte hinzu, was ein direktes P2P zu einer Lösung macht, die eher zu vernachlässigen ist.
-
Komplexe Synchronisation. Wenn jeder Client auch gleichzeitig ein Server ist, entsteht die Frage, wer die Autorität über die zu synchronisierenden Objekte besitzt. In diesem Fall entsteht die Notwendigkeit für einen besonderen Konsensmechanismus, welcher aus den vielen Angaben einen gültigen Game-State ermittelt und akzeptiert. Solche Mechanismen sind allerdings komplex und fehleranfällig und sollten möglichst vermieden werden.
-
Schwerfällige Skalierung. In einem Direct P2P Netzwerk sind alle Clients mit allen anderen Clients verbunden. Mit jedem neuen Client steigt die Anzahl der Verbindungen signifikant.
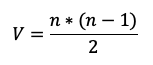
Wenn n der Anzahl der Client entspricht, hat eine Anwendung mit 4 Clients 6 Verbindungen, eine Anwendung mit 8 Clients schon 28 Verbindungen, bei 12 Clients sind es 66 Verbindungen.
Direct P2P wurde in diesem Beitrag nur der Vollständigkeit halber erwähnt. Die Details sollten zeigen, dass etablierte Multiplayer-SDKs diese Lösung bewusst nicht unterstützen.
Dedicated Server
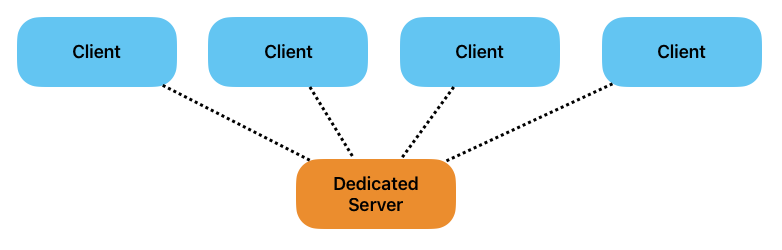
Die wohl verbreitete Lösung für eine robuste Multiplayer-Lösung. Dabei wird die Server-Runtime auf einem dedizierten Server gehostet, worauf sich einzelne Clients verbinden.
-
Fair. Im Gegensatz zu P2P-Netzwerken besitzt keiner der Clients einen Vorteil, wenn eine größere Latenz auftritt. Alle Clients bekommen gleichzeitig State-Changes, unter der Annahme, dass alle eine ähnlich starke Internet-Verbindung haben.
-
Sicher. Ohne einen Host, hat kein Client die Möglichkeit auf alle Server-Authoritative Objekte zuzugreifen, was Cheating wesentlich schwerer macht.
-
Skalierbar. Mit jeder neuen Verbindung kommt nur eine weitere Verbindung zwischen Server und Client zustande. Für Clients ist es hinfällig, wie viele andere Clients verbunden sind. Einzig der Server muss nun bei einem State-Change an einen weiteren Client die Daten senden.
-
Verfügbarkeit. Ohne die Notwendigkeit für einen Host, haben Entwickler*innen die volle Kontrolle über die Qualität der Multiplayer-Erfahrung. Sie selbst können bestimmen, wie viel Rechenleistung die Server-Hardware haben soll. Besonders bei Zielgruppen mit eher leistungsschwacher Hardware, kann ein dedizierter Server für Entlastung auf User-Seite sorgen.
Software-Development Kits
State-Management ist ein komplex und besonders bei Echtzeit-Anwendungen wie XR-Anwendungen und Videospielen ein wichtiges Thema. Für die vielfältigen und meist sehr einzigartigen Anforderungen bedarf es umfassende Werkzeuge, die Entwickler*innen die Arbeit an einem Multiplayer erleichtern. Diese Werkzeuge bzw. die Code-Base für Multiplayer-Funktionalitäten wird häufig auch Netcode bezeichnet.
Integration
In diesem Abschnitt soll es nicht um konkrete SDKs gehen, sondern um die Grundfunktionen, welche man von SDKs erwarten sollte. Werden diese nicht geboten, sollte man sich den Aufwand bewusstwerden, diese Funktionen selbst zu implementieren.
-
Game Engine. Wenn für die Entwicklung eine Game Engine verwendet wird, bieten beispielsweise Unity und Unreal eigene SDKs für die Entwicklung von Multiplayer-Features. Eine Game Engine kann aus der Software-Perspektive als ein eigenes, riesiges Framework mit GUI betrachtet werden, welches eine eigene Design-Philosophie verfolgt, wie bspw. Videospiele entwickelt werden sollten. Ein hauseigenes SDK ist dann nicht mehr als ein Plugin zu diesen Frameworks und ist dann besonders attraktiv, wenn das Projekt streng an die Design-Philosophie der Engine richtet.
-
Third-Party. Darüber hinaus gibt es auch abstrakter gehaltene SDKs, welche agnostisch zu Game Engines oder Frameworks sind. Die Flexibilität geht dann wiederum auf Kosten Entwicklungszeit, die notwendig ist, um Schnittstellen zwischen SDK und Game Engine zu schaffen. Verwendet man bspw. in Unity eine Rigidbody-Komponente, für welche in dem offiziellen Unity-SDK eine vorgefertigte Netzwerk-Lösung existiert, so müssen Entwickler*innen an dieser Stelle eigenen Netcode schreiben.
-
Egal welchen Weg man wählt, alle SDKs geben Werkzeuge an die Hand die verschiedenen Hosting- / Topologie-Varianten zu unterstützen und State über das Netzwerk an die Clients zu kommunizieren. Im nächsten Abschnitt gehen wir auf diese Werkzeuge ein.
Transport Layer
Multiplayer-SDKs bieten eine große Bandbreite an Werkzeugen für die Entwicklung und nehmen Entwickler*innen dabei in vielen Aspekten Arbeit ab – angefangen beim Transport Layer. Ein Transport Layer stellt die Verbindung zwischen den Anwendungen und der Hosts in einem Netzwerk her und sorgt für einen zuverlässigen Austausch.
Der Transport Layer eines SDKs kann folgende Funktionen enthalten:
-
Connection-oriented Kommunikation garantiert eine robuste Verbindung mittels eines Handshake-Protocols.
-
Die Daten-Integrität wird bei fehlerhaften oder verlorenen Paketen durch Retransmission wieder hergestellt.
-
Bei verlorenen Paketen, hoher Netzwerk-Latenz und / oder Ausfall der Hardware kann dafür gesorgt werden, dass die Paket-Reihenfolge wiederhergestellt wird.
-
Der Traffic wird reguliert, um die Netzwerk-Performance nicht unnötig zu belasten.
Tooling
Genutzt wird der Transport Layer von einer Vielzahl an Modulen und Funktionen, welche den Game State an andere Clients oder Server versenden wollen. Es gibt hierbei Reihe an Möglichkeiten, um State zu kommunizieren, welche sich auf die verschiedenen Arten der Synchronisierung zurückführen lassen, welche in einem früheren Abschnitt behandelt wurden.
Folgend die zwei wichtigsten Werkzeuge, welche jedes Multiplayer-SDK implementieren sollte:
Netzwerk Variablen
Kontinuierliche Synchronisierung, wie ein Ball bei einer Fußballsimulation, müssen so schnell und verlässlich wie möglich mit allen Clients synchronisiert werden. Darum bieten SDKs in der Regel einen Variablentyp, welcher es ermöglicht Variablen über das Netzwerk synchronisieren zu lassen. Diese werden dann je nach Implementierung bei jeder Veränderung und / oder in einer bestimmten Frequenz synchronisiert. Hier gilt auch wieder festzulegen, wer die Autorität über die Variable hat. In Unitys hauseigener SDK namens Netcode for Gameobjects würde solch eine Variable wie folgt verwendet werden.
Die Klasse, welche die Netzwerk-Variable verwenden möchte, muss von NetworkBehaviour erben. Die NetworkBehaviour-Klasse erbt von der allgemein bekannten MonoBehaviour-Klasse und erweitert diese um die Netzwerk-Funktionalitäten mit Methoden wie bool IsOwner() oder int GetNetworkObjectId() und auch Callback-Funktionen wie OnNetworkSpawn(), um auf Netzwerk-Events zu reagieren.
Anschließend lässt sich die Klasse NetworkVariable verwenden, um eine Netzwerk-Variable zu deklarieren.
private NetworkVariable<int> m_SomeValue = new NetworkVariable<int>();
Der Wert der Variable wird allerdings mithilfe eines eigenen Attributs verändern.
m_SomeValue.Value = k_InitialValue;
Um über Veränderungen an der Variable in Kenntnis gesetzt zu werden, nutzt man die dafür vorgesehene Callback-Funktion.
m_SomeValue.OnValueChanged += OnSomeValueChanged;
Versucht ein Client die Variable zu verändern, besitzt aber nicht Autorität darüber, schlägt dieser Funktions-Aufruf fehl. Sieh dir die Dokumentation an, mehr Informationen über die NetworkVariable-Klasse.
Remote Procedure Calls (RPCs)
Bei eventbasierter Synchronisierung sind vor allem RPCs nützlich. Diese geben die Möglichkeit bei Server und / oder Clients Funktionen auszuführen. Anhand von RPCs wird auch deutlich, warum es wichtig ist, dass Server- und Client-Runtime dieselbe Code-Basis verwenden. Denn damit ein RPC die richtige Instanz in der Anwendung findet, um dort einen Funktionsaufruf durchzuführen, muss diese Instanz denselben logischen Pfad besitzen, wie die Anwendung, welche den RPC abgeschickt hat.
Im Falle von Netcode for Gameobjects erstellt man einen RPC wie folgt.
Angenommen wir haben ein Partikel-System, welches gleichzeitig auf allen Clients gestartet werden soll. In diesem Fall existiert die ClientRpc-Annotation.
[ClientRpc]
public void PlayParticlesClientRpc() {
ParticleSystem.Play();
}
Diese Funktion könnte allerdings nur vom Server bzw. vom Host ausgeführt werden. Da Netcode for Gameobjects es nicht erlaubt, ClientRpc von Clients aufzurufen. Falls wir aber von einem Client aus, den Effekt auslösen wollen ist der Umweg über einen ServerRpc notwendig, welcher dann den ClientRpc ausführt.
[ServerRpc]
public void PlayParticlesServerRpc() {
PlayParticlesClientRpc();
}
In diesem Fall würde ein Client den ServerRpc ausführen. Der Server erhält den RPC und führt anschließend auf allen Clients, inklusive den, der den ursprünglichen RPC abgesetzt hat. Das mag zunächst umständlich erscheinen. Doch neben dem Vorteil, dass so die Autorität über den Funktion-Aufruf beim Server liegt, hat es auch zur Folge, dass die Funktion auf allen Clients gleichzeitig ausgeführt wird. Bei hoher und / oder unterschiedlicher Latenz der Clients kann es denn noch unterschiedlichen Erlebnissen kommen.
Spezifische Lösungen
Neben den eben erwähnten Lösungen gibt es noch etliche für Game Engines zugeschnittene Lösungen. Nicht jede Game Engine hat ein eigenes Multiplayer-SDK, doch meist gibt es zumindest Schnittstellen.
Auch liefern SDKs unterschiedliche Lösungen für sehr spezifische Probleme, die aber nicht in jedem Projekt auftreten müssen. Ein sehr bekanntes Beispiel ist Dead Reckoning.
Dead Reckoning ist eine Technik im Multiplayer-Game-Development, die verwendet wird, um die Position und Bewegung von Objekten vorherzusagen und zu interpolieren, um eine reibungslose und verzögerungsfreie Darstellung zu gewährleisten. Da Latenz häufig auftreten, sendet der Server nicht ständig die genaue Position aller Objekte an alle Clients. Stattdessen berechnen die Clients die Positionen basierend auf den zuletzt empfangenen Daten und den erwarteten Bewegungen. Wenn neue Daten eintreffen, passen sie die Vorhersagen an, um Diskrepanzen zu minimieren und eine möglichst flüssige Darstellung zu gewährleisten. Dies verbessert das Benutzer*innen-Erlebnis, indem es Lag reduziert und die Synchronisation zwischen den Clients verbessert.
Jede Anwendung ist einzigartig
In diesem Beitrag haben wir uns zwar im Detail mit Werkzeugen beschäftigt, die Entwickler*innen zur Verfügung stehen, wenn sie eine Multiuser-Anwendung entwickeln möchten. Doch war das lediglich ein kleiner Einblick, um ein grundsätzliches Verständnis aufzubauen. Neben den erwähnten Möglichkeiten gibt es viele weitere, die in ihren Anwendungsgebieten so speziell sind, dass es wenig Sinn hat, sie an dieser Stelle zu erwähnen, ohne Verwirrung zu stiften. Wichtig ist nur zu verstehen, dass diese Werkzeuge nicht alle verwendet werden müssen und sollen. Jede Anwendung ist einzigartig und sollte dem entsprechend behandelt werden. Die Auswahl der richtigen Werkzeuge setzt ein tiefes Verständnis für die Struktur der Anwendung voraus und sollte immer mit Bedacht gewählt werden, um spätere Umbauten zu vermeiden.
Im nächsten Artikel gehen wir näher auf die realen Optionen ein, welche Entwickler*innen haben, um mit der Entwicklung eines Multiuser-Features zu starten. Zusätzlich wird ein Fragenkatalog vorgestellt, um leichter Entscheidungen bezüglich Infrastruktur und Software treffen zu können.